“From today, painting is dead.” The sentence is attributed to the French painter Paul Delaroche after he first saw a daguerreotype. The quote reminds us of a real fear of the time: photography had arrived, and painting seemed to have lost its old duty of capturing the world as it appears. But painting did not die. On the contrary, it became freer. Once the camera could reproduce the look of things, painters could ask better questions: how seeing feels; how memory rearranges what it keeps; how emotion bends reality; how time, movement, dreams, or invisible structures might be given a body. Out of this release came much of modern art: Impressionism, Symbolism, Expressionism, Cubism, Abstraction, Surrealism.
Tim Gowers: AI Is Already Producing PhD-Level Mathematics.
The lower bound for contributing to mathematics will now be to prove something that LLMs can’t prove, rather than simply to prove something that nobody has proved up to now and that at least somebody finds interesting.
Although this doesn’t announce the end of mathematics or science, it definitely changes the ground under the feet of those still learning how to enter this endeavor. And the ground is moving quickly. AI models are becoming astonishingly good at an unprecedented pace, and as long as “some” original research exists, there will be new data that prevents the whole system from “cannibalizing” itself. This means we may still need humans to do original work, but perhaps fewer of them, and this is exactly where the unease begins!
Many researchers are already working with a small team of AI assistants: testing ideas faster, searching more widely, and doing work that would have been impossible alone. So, for a researcher who can secure a position at a prestigious institution with access to the latest models, the future may look bright. But for others, it can be a fragile brightness. Even the privileged researcher must make sure not to become the least necessary member of that team! Academia, after all, is not only a place for creativity and originality. It also has a corporate face: metrics, rankings, temporary contracts, visas, deliverables, and replaceable people.
State-of-the-art AI is not free, not cheap, and not available to everyone in the same way. As these tools are becoming part of the research ecosystem, access to them will become another hidden inequality in academia. On top of this, major AI companies are not like public libraries; they have owners, markets, incentives, and conversations with Big Brother. So the question is no longer only whether LLMs can do research. They already can do some of it. The question is what kind of academic world we build around them: who becomes freer, who becomes replaceable, and who is left outside the door.
Restored portrait of a Daguerreotypist displaying daguerreotypes and cases. From Wikipedia.
How did we decide to call a tree “tree”? A bird “bird”? Not now, but in the early days, when there could have been different ways to name or define something.
I imagine it was messy at first. People pointed, made noises, copied each other, corrected each other, and slowly converged to something. Different groups might have had different oral representations, in this context, words, for the color blue, and over time, those differences narrowed, through contact and habit, until a few names survived. Then we learned another trick. Instead of making a new word for everything, we started combining words. We built grammar. We discovered that a small set of sounds could be arranged to carry much more than any single label. But how long did it take us to find a way to carry our feelings into materialized words, the first time we tried to express fear, a thought, a doubt?
Language may have become possible by reducing the space of possibilities around a subject of interest. We agree on forms to reduce noise. We make things clearer by making them less vague. That is how we can finally have a conversation. Words give shape to what would otherwise stay obscure. For objects, it is straightforward. For concepts, it is harder, but we still do it.
Meaning is personal. We use the exact words, but we are rarely talking about the same thing. A tree is a woody plant for most people, but for one, it might be a pine in the dark, and for the other, an apple tree near home. Words never travel light; every time one appears, it drags a pile of private assumptions or attributes behind it. When Western philosophers wrote “man,” they were most likely thinking of white men, more or less their own reflection, and then calling it universal. And when my friend Jane says, “I’m looking for a guy with a genuine heart who makes me laugh,” she means someone she finds attractive, socially acceptable, financially sorted, emotionally safe, and amusing in a very specific, non-threatening way.
We pretend we share meanings and unconsciously ignore how much extra baggage each word is smuggling in. Yet, most of the time, we get by because language has settled. Not because it is perfect, but because it is stable enough. Words become shared habits. They are used almost the same way across a community, which makes conversation possible. But it also does something else. Over time, words get trapped in their usual meanings. They stop feeling like choices and start feeling like nature. Over centuries, a word becomes a well-worn path: efficient, familiar, and increasingly difficult to leave. We forget that each word is vague until we decide not to treat it as vague. We treat the path as the landscape.
This is where poetry matters.
A poet enlarges the space of possibility inside words, and hence introduces a larger universe to us. In ordinary life, every word masks something. It hides the richness of what it points to, because it must be usable quickly. Grammar, too, can become a kind of mask: not only arranging meaning, but constraining it, forcing thought into customary channels. Some notions remain pressed against the back wall of what is sayable, suffocated by routine phrasing.
Poetry resists this settling. It stretches a word beyond its standard use, defamiliarizes it, and lets it touch unexpected neighbors. It does not merely describe; it makes things appear again, as if for the first time. That is why a poem is rarely transparent on first reading. It is not only that the reader is slow; it is that the language has been reshaped. The poem asks you to inhabit words differently. Whether a poem is long or short does not matter; what matters is that it changes the universe you thought those words lived in.
This is also why “reasonable” comparisons can be a trap when reading poetry. A comparison can be correct and still dead in a poem. The metaphors that truly wake us often feel strange, even a bit absurd at first. They provoke the imagination. They do not merely carry meaning; they multiply it. In that sense, the poem behaves as any artwork may do: it signifies beyond a single paraphrase, yet it remains tightly held by form, so that the reader is guided rather than lost. That’s why “the truest poetry is the most feigning”.
At the same time, once a poetic move becomes familiar, it loses force, because it becomes part of the common language!
A metaphor that once surprised can become a button we press automatically. The first person to liken a woman’s cheeks to a rose, or her long black hair to the longest winter night, may be a poet; the thousandth is usually only repeating, so even if it is beautiful, it is no longer poetry. When someone says, “Your lips are a glass of wine to me,” simply because it is the kind of thing one says, language is no longer discovery; it is habit. In that moment, the speaker is borrowing another person’s bag of words. Hence, the common language.
This is not only an aesthetic failure; it is a failure of attention and sincerity. Prefabricated phrases allow us to speak without thinking. Worse, they allow us to feel without fully feeling, because the emotion arrives already packaged by culture. A worn-out metaphor is not merely unoriginal; it can be a way of outsourcing experience. To be a poet, and, in a deeper sense, to be a lover or a thinker, I believe we must see and say for ourselves. Repeating another’s vision is not seeing. It is sleepwalking through language.
Poetry introduces new worlds by changing not only meanings but the kinds of explanations we permit.
In poems, we can attribute human emotion to nature. The wind “wants,” the sea “remembers,” the night “refuses.” This can happen without any claim of literal causation. Poetry permits a rhetorical because, knowingly untrue in the scientific sense, but emotionally or aesthetically satisfying. The laurel exists because Daphne fled Apollo. The nightingale sings because it mourns. These are not causes; they are invented reasons, poetic ones. They do not explain the world as it is; they create a world that could be, a universe where feeling is a principle of order.
In this sense, poetry is not merely language with ornaments. It is language stretching its own rules and opening a new field of meaning, one that cannot be reduced to definitions alone. By the same logic, the poetic can arise in any human endeavor. This is why Tarkovsky’s cinema is often called poetic.
Words materialize the nothingness of things, yet they do so differently for concepts than for objects. Hence, every word masks something. The Poet unmasks it. When words are gathered into sentences, obedient to grammar, they often conceal more than they reveal. The order is useful, of course, but it is also a kind of fence. Some notions press against its bars and cannot pass through; they are suffocated there. Poetry not only gives words new meanings, but it also alters the ease and shape of the structures we speak in. It makes room. And in making room, it builds a new universe.
Storytelling, though, operates differently.
A story typically does not expand language itself. It uses language as it already exists. Its power lies not in reshaping the meanings of words, but in arranging events into a sequence that can be lived through. In that sense, narrative is closer to scientific modeling than to poetry, in my view! Science abstracts reality into models to understand interactions between particles, people, systems, and to explore what we have not directly observed. A model lets us test possibilities and ask “what if?” with discipline.
Stories do something similar in human terms. They are simulations of life. Through narrative, we rehearse motives, consequences, risk, choice, and regret. We experience situations we may never encounter directly, and we learn patterns of feeling and action without paying the full cost in real life. This is why people reach for stories when trying to explain reality: narratives feel true not because they are factual, but because they model experience in a form we recognize.
So, poetry and storytelling both build worlds, but they do so differently. A story builds a world by sequence, in the language. Poetry builds a world by meaning, by returning words to their openness, and letting language become new again. That is why poetry may be the highest thing the mind has made.
After writing these notes, I realized that Heidegger and L. P. Yakubinsky, separately, have written extensively on closely related themes, often under similar titles. I have not read their work yet, but I am now very curious to see what they have to say.
I was not happy about the way people use the word “Emergence” in the scientific discourse. So, gathered my thoughts and picked my favorite references to pen down what emergence means!
In this perspective paper, I take a clear-eyed look at emergence as it manifests in real systems, ranging from flocking birds to magnets to herd immunity in social networks. I explain how complex behaviors and patterns can emerge from simple parts interacting locally, and why these large-scale phenomena often can’t be easily understood just by looking at the pieces alone. Instead of getting lost in buzzwords, I break down the idea using concrete examples, showing that emergence isn’t magic, it’s measurable, physical, and beneficial for making sense of the multi-layered complex world we live in.
We’ve all heard the idea that if you reach a certain percentage of immunity in a population, you achieve herd immunity. But what if it’s not just about the percentage? What if how people are connected plays a huge role too? This is what our new PNAS paper is all about—how herd immunity, whether from natural infection or vaccination, interacts with our social networks.
Every epidemic intervention, such as vaccination, mask mandates, school closures, and contact tracing, that we apply to a population usually influences some local properties of our social network by altering the connections or interactions between people. These local effects then propagate throughout the entire network, and depending on the population’s structure, they either get amplified or eventually fade away, leaving the intervention almost useless. We model social networks with random graphs. In this picture, every person is represented by a node (a point in space and maybe in time), and a link (a line segment) between two nodes represents a contact or connection between two people. A collection of nodes with some specific connection pattern represents an ideal who-contacts-whom map of the population. An epidemic intervention changes the contact pattern of such random graphs.
Herd Immunity Thanks to Vaccination
Take vaccination as an example. In the simplest scenario, with a perfect vaccine, we immunize the vaccinated individuals and block the transmission routes to their neighbors, which means removing a certain number of batches — nodes with their connecting links — from the original network. Sometimes, these batches form larger batches and together, dismantle the network. This phenomenon is known as percolation in scientific jargon. We say immunity has percolated through the target population if, with sufficient vaccination, every local infection dies out as it is contained within its neighborhood. The benefit of vaccination is twofold. First, some people gain immunity as a direct effect of vaccination (removed nodes), and second, the remaining unvaccinated people, despite not being directly immunized, gain protection by being disconnected from the infection routes. In practice, the challenge remains to determine how many people and in what order and pattern we need to vaccinate to achieve population-level immunity, or, in epidemiological terms, herd immunity.
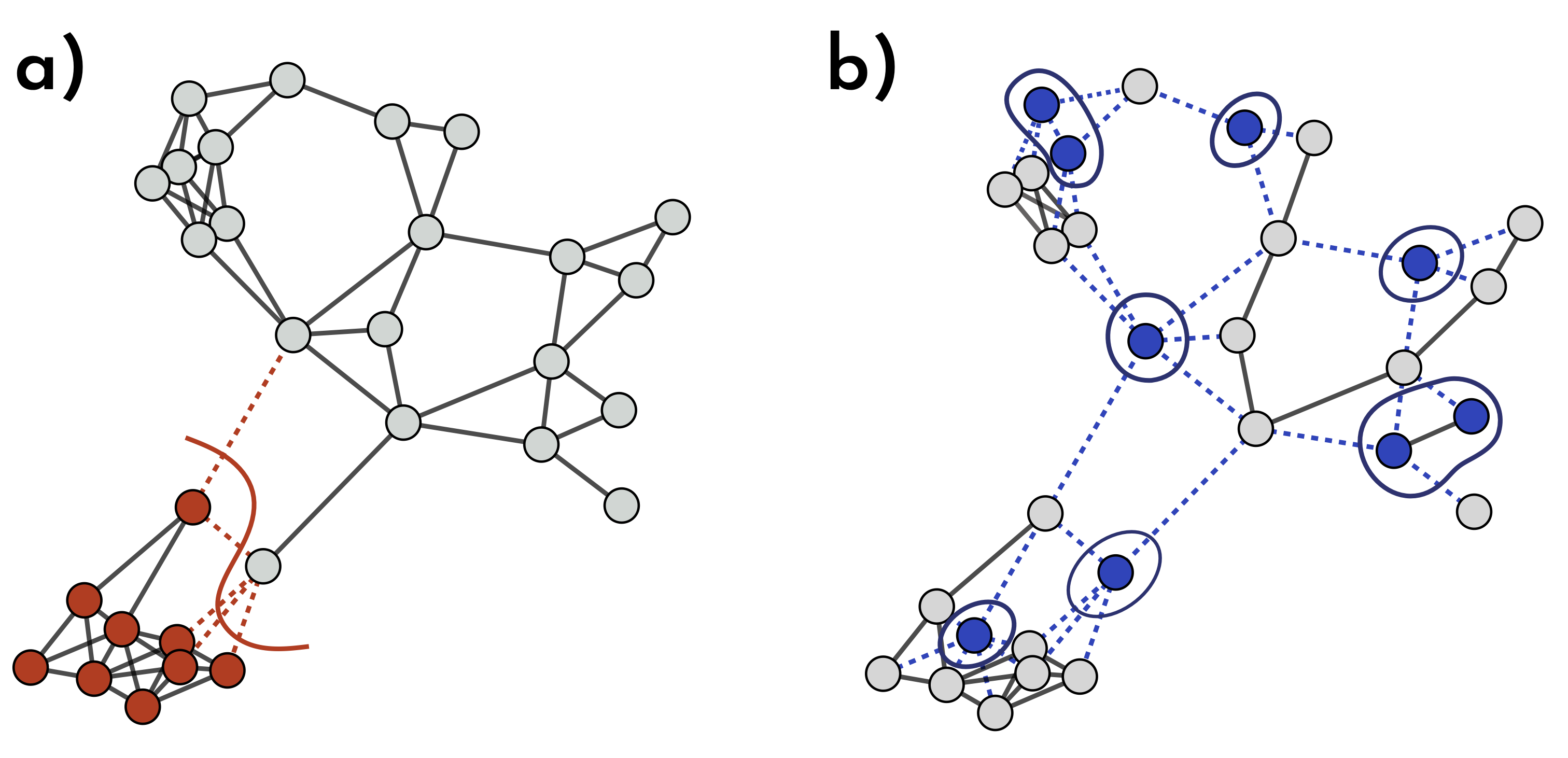
Fig. 1: How Different Immunization Strategies Protect the Network. In (a) & (b), the same number of nodes is immunized, but their placement makes a big difference. In (a), immune nodes (red) form a close batch, blocking only a few virus pathways (dotted red lines) and providing limited extra protection. In (b), vaccinated nodes (blue) are scattered across the network, removing a more spread-out batch of nodes and links. This scattered setup disrupts many more transmission routes, giving the entire network stronger, broader immunity.
A simple way to find the herd immunity threshold is to consider exponential growth for the early stage of an epidemic, where each infected individual, on average, infects $R_0$ more people. Now, if we randomly vaccinate a fraction $v$ of the population, the number of secondary infections, $R_{e},$ becomes $R_{e}=(1-v)R_0$, meaning each person now infects $vR_0$ fewer people. If $R_{e}$ falls below one, instead of exponential growth, we see a decline, and the disease quickly dies out. So, the herd immunity threshold is the fraction $v_c$ that satisfies this equation $1=R_0(1-v_c)%$. Solving this gives the threshold: $$v_c = 1 – \frac{1}{R_0}.$$
Fig. 2: By randomly vaccinating $v$ fraction of people, we reduce the number of secondary infections, and if we manage to reduce it enough, the diseases die out immediately.
If we set $R_0=3$, as some studies did early in the COVID-19 pandemic, the equation above gives $v_c = 1 -1/3 \approx 0.7$. This might ring a bell, as you may have heard about the 70% vaccination target for reaching herd immunity in the media. In mathematical epidemiology, $R_0$ is known as the basic reproduction number, and $R_e$ is called the effective reproduction number. This reasoning has been widely used to estimate the herd immunity threshold.
However, we now understand that this approach needs to be revised in many instances because it oversimplifies the complexities of real-world scenarios. This model assumes that everyone has an equal chance of interacting with anyone else, regardless of their location, occupation, age, or interests. In reality, we do not live in a giant cocktail shaker where we constantly bump into one another. We interact with people around us in different ways and at other times. Our social and health behaviors significantly affect the outcome of epidemic spread and can hinder the effectiveness of interventions. To consider these complexities, we need to put the networked structure of the human population in our modeling assumptions. Let’s follow a yet simple but more realistic approach.
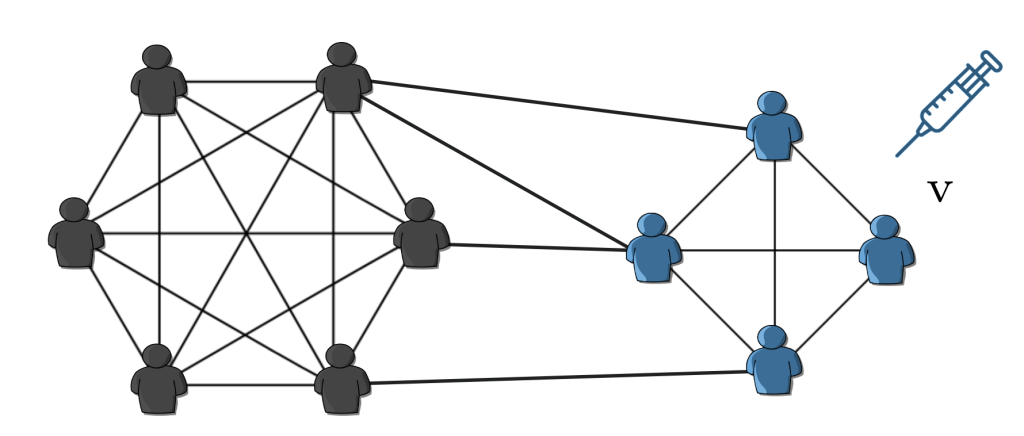
Fig.3: In a fully-mixed population, everyone can interact with everyone at any time! In reality, however, we do not live in a giant cocktail shaker where we constantly bump into one another!
Imagine a population where people have different numbers of connections, and vaccinated individuals are more likely to interact with other vaccinated people, while unvaccinated folks also tend to stick to their own group. This is a familiar scenario: in most populations, vaccine uptake doesn’t result in a perfectly even distribution. There are often vaccine-hesitant individuals who primarily engage with others who share their views. This social tendency, where similarity drives connections, is known as homophily in sociology. “Birds of a Feather…” and all that.
Fig. 4: A more realistic transmission network where each person interacts with a different number of individuals, and interactions are more likely to occur between people with the same vaccination status. This network has a positive Coleman homophily index based on the vaccination.
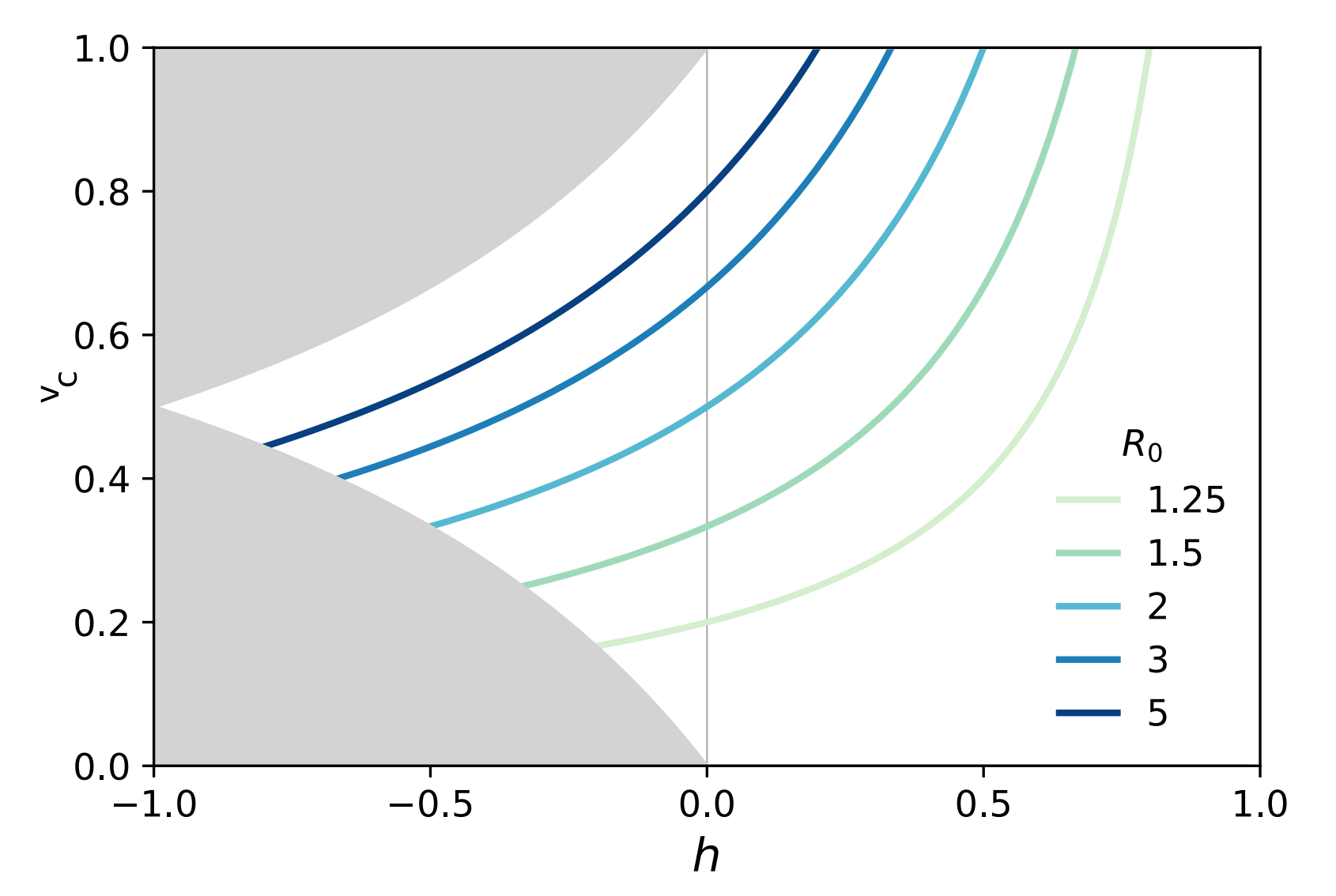
We can measure the degree of vaccine homophily, $h$, based on the fraction of vaccinated people and the likelihood that a vaccinated person connects with either vaccinated or unvaccinated individuals. The homophily value, also known as the Coleman homophily index, ranges from -1 to 1. When $h=0$, people interact regardless of their vaccination status. A positive $h$ indicates a preference for same-status connections, with larger values reflecting a more substantial bias. Now, the question arises: given this specific pattern of connections controlled by $h$, how does our previous equation for the herd immunity threshold change? Researchers at Aalto University in Finland have shown that incorporating these nuances into the model modifies the herd immunity threshold equation to $$v_c = \frac{1}{1 – h}\left(1 – \frac{1}{R_0}\right).$$ To understand this equation, let’s first set $h = 0$, representing a fully mixed population with no preference in interactions. This returns the original equation, assuming vaccines are evenly distributed. It implies that, as long as $R_0$ is known, we can calculate the epidemic threshold regardless of the connections between individuals. However, when $h \neq 0$ , things change significantly. Fig. 5 shows how the herd immunity threshold varies with different $R_0$ values as a function of vaccination homophily. For example, in a population with $h = 0.5$ when $R_0 = 2$, the herd immunity threshold reaches 1, meaning every single individual must be vaccinated to achieve herd immunity. When vaccination homophily exceeds $1/R_0$, herd immunity becomes unachievable as indirect protection diminishes entirely.
Fig. 5: As vaccination homophily increases, the herd immunity threshold rises, eventually reaching a ceiling. This indicates that there is no indirect benefit from vaccination beyond a certain point, when $h \geq 1/R_0$, meaning herd immunity becomes unattainable.
This approach, while more realistic than the previous one, still doesn’t fully capture real-life complexities. However, it provides a foundation for understanding herd immunity and helps generate more refined research questions. Models that assume uniformly random connections between individuals—ignoring how people are actually connected—are called mean-field models. By averaging out individual differences, they treat everyone as equally likely to interact with anyone else. While this simplification is useful for deriving general insights, it overlooks the finer details of network structures, where social dynamics, proximity, and individual connectivity significantly influence the spread of immunity and disease. We’ll revisit these concepts later.
Herd Immunity Thanks to Natural Infection
Think of herd immunity as a firewall: the more individuals in a population who are immune, the more difficult it is for the disease to reach those who are vulnerable. This protection is nonlinear—each additional immune person often enhances the firewall, providing even greater protection for everyone. In addition to vaccination, herd immunity can also be achieved through natural infection. Vaccination introduces a weakened or inactive form of the pathogen, or, in the case of mRNA vaccines, a genetic blueprint that instructs cells to produce a harmless protein, thereby stimulating an immune response. Natural infection, on the other hand, occurs when people contract an illness and develop immunity after recovering. In both cases, each node gains a sort of immunity memory, which may wane after some time.
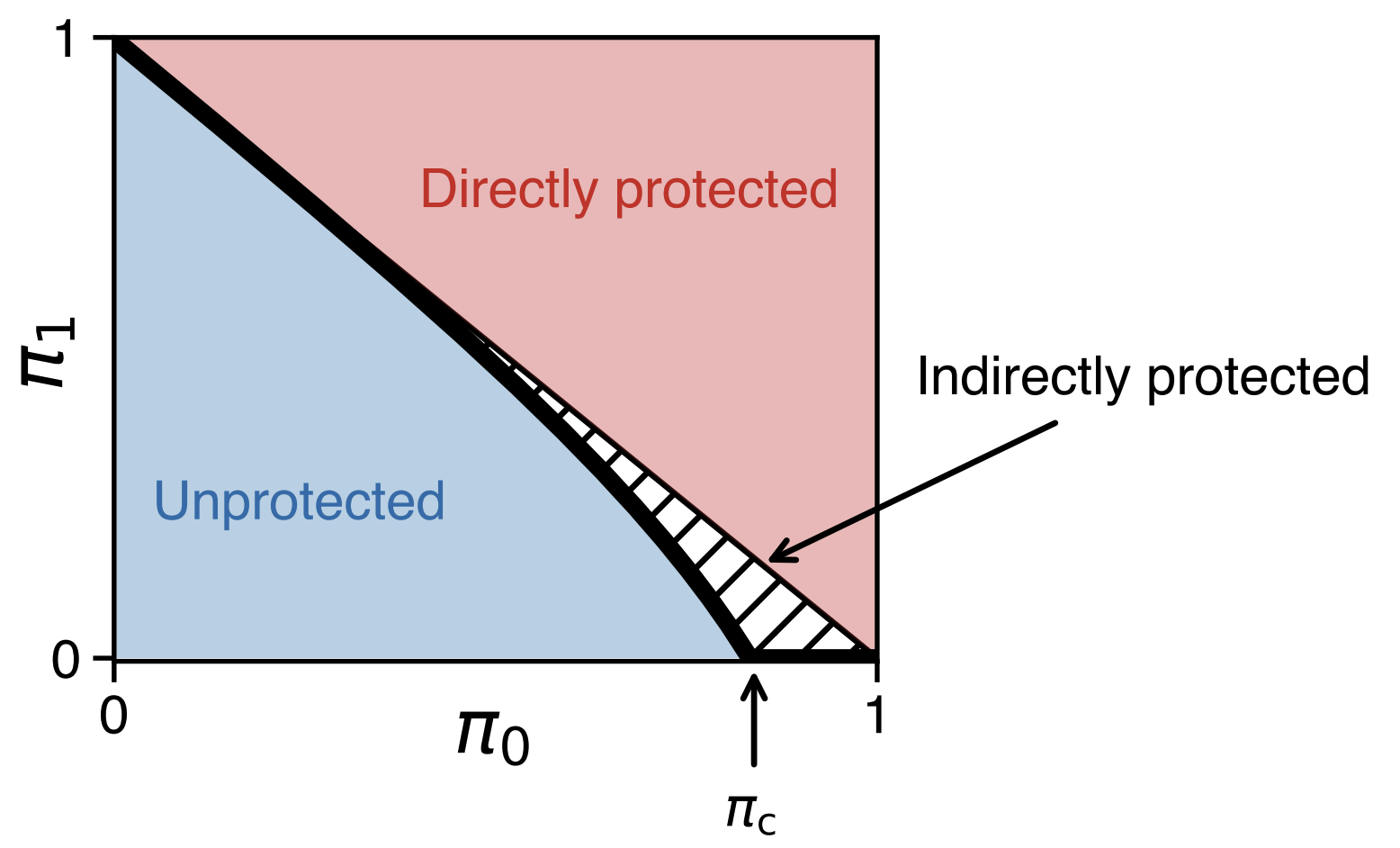
Fig. 6: Herd immunity is larger than the sum of individual immunities. The horizontal axis ($\pi_0$) shows the fraction of immune people, while the vertical axis ($\pi_1$) represents the size of the largest connected group still at risk of infection—think of $\pi_0$ and $\pi_1$ as the potential number of people infected in the first and second waves of the epidemic, respectively. At a certain immunity level, $\pi_c$, the disease can no longer easily spread, creating a ‘herd immunity’ effect where even non-immune individuals are protected.
Vaccination and natural immunity typically operate differently in a network. Take another look at Fig. 1. In panel (a), we see a scenario resembling immunity acquired through recovery: the infection likely started near the bottom of the network, spreading to neighboring nodes as it progressed. In contrast, panel (b) doesn’t reflect natural immunity since there’s no clear path between immune nodes. Instead, this pattern suggests immunity from an external factor, like vaccination. Although both networks have the same number of immune nodes, the level of protection across the network differs. Kermack and McKendrick, in their seminal paper, derived a mathematical expression for disease-induced herd immunity, showing that an epidemic of a disease that grants immunity upon recovery can end before the entire susceptible population is infected. Without considering any network structure, disease-induced and vaccination-induced herd immunity are mathematically equivalent. However, this equivalence falls apart when contact patterns are not homogeneous.
Networks are all about connections—some people, like social butterflies, have many connections, while others have fewer, closer bonds. This variation, known as degree heterogeneity, refers to the fact that specific individuals, referred to as superspreaders, can infect a large number of others if they contract a disease. Connections are also not entirely random; they’re influenced by physical proximity. People who live or work near each other are more likely to be connected, a concept called spatiality. As Tobler’s First Law of Geography says:
Everything is related to everything else, but near things are more related than distant things.
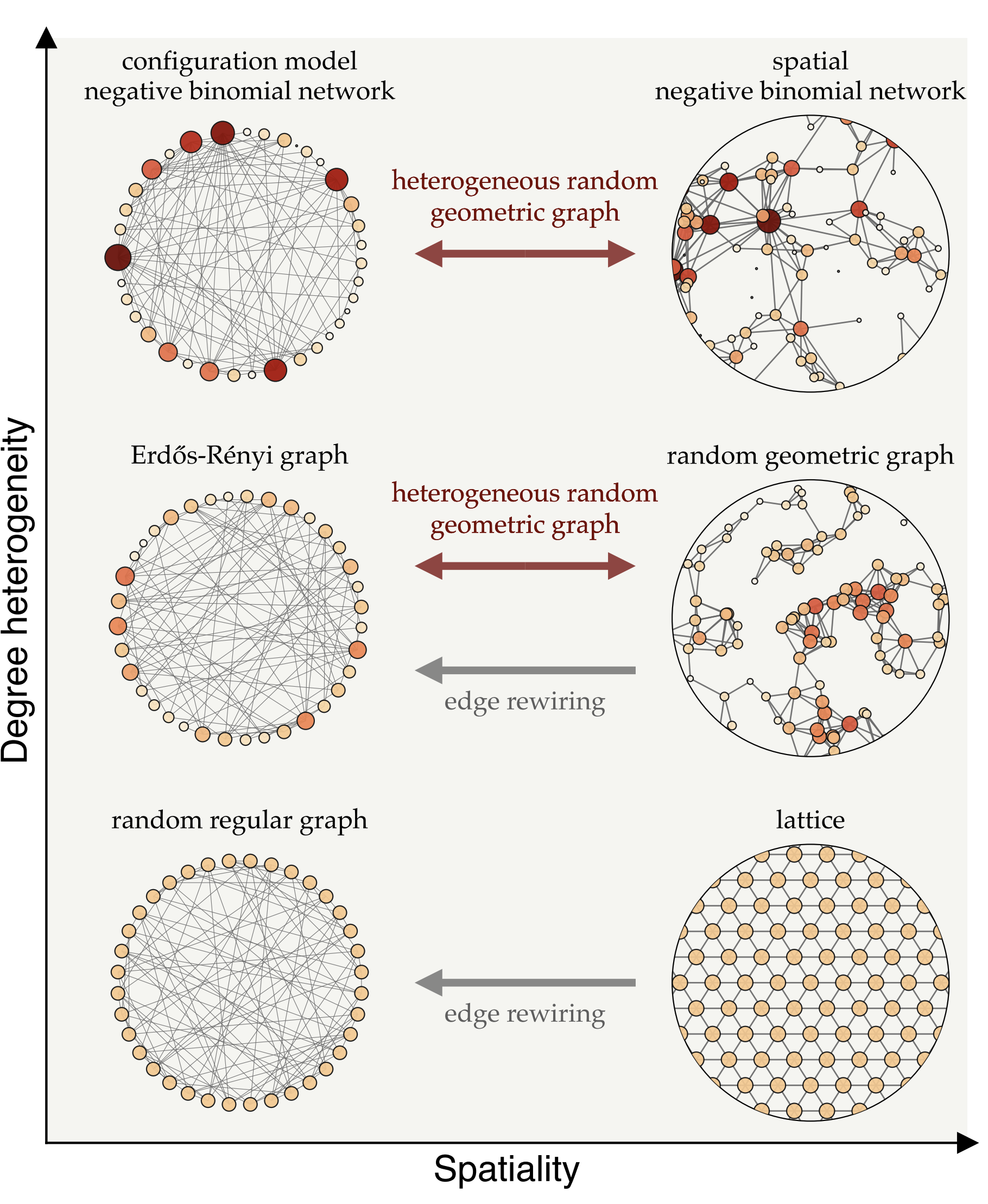
Fig. 7: Different types of network models, positioned according to their degree-heterogeneity (vertical axis) and spatiality (horizontal axis). Degree heterogeneity captures the range of connections individuals have—from highly connected hubs to those with few links—while spatiality represents how much connections are influenced by physical proximity.
We can transition between these network types using mathematical techniques that adjust their heterogeneity and spatiality. For instance, edge rewiring increases randomness in connections while preserving the network’s degree structure, while other methods introduce spatial constraints without altering degree variations. These models enable us to investigate how network structure influences the spread of immunity and disease.
On the left side of Fig. 7, we see a range of network models where connections aren’t constrained by proximity, but instead vary in terms of degree heterogeneity. The top-left model, known as the configuration model, is particularly useful for representing superspreaders—individuals with an exceptionally high number of connections, often referred to as infection hubs. This framework allows us to simulate populations with a wide variation in connections, where a few superspreaders are highly connected and play a key role in disease transmission. In network models that allow for such degree heterogeneity, hubs are more likely to become infected early due to their numerous connections, and once recovered, they no longer fuel the epidemic, which can significantly slow disease spread. This suggests that, assuming infection is not overly harmful, disease-induced immunity can be more effective than random vaccination in such networks. Random vaccination is less likely to target superspreaders, leaving them susceptible and enabling them to continue spreading the disease. Therefore, there are mathematical and data-driven studies suggesting that disease-induced immunity offer an advantage over vaccination by targeting superspreaders who drive transmission.
Early in the COVID-19 pandemic, Sweden adopted a strategy that minimized interventions, aiming to allow natural immunity to develop through superspreaders and enhance overall population immunity. However, this approach faced significant challenges, leading Sweden to reassess and adjust its policies. One reason for its shortcomings was that degree heterogeneity—variation in the number of connections—is just one of many factors that influence the spread of epidemics. It turns out that disease-induced immunity is driven not only by the concentration of immunity among socially active individuals, as already identified in mean-field models, but also by another counteracting mechanism inherent to network models.
The Spatial Blueprint of Immunity in Networks
As we show in our new paper, while superspreaders do give disease-induced immunity a clear edge, that’s only part of the story. Our mathematical investigation into herd immunity reveals two competing mechanisms: preferential immunity and localization. Preferential immunity occurs when highly connected individuals—superspreaders—are more likely to get infected early, which can actually strengthen herd immunity. Once immune, these individuals act as a firewall, limiting the disease’s ability to spread widely. Localization, however, refers to outbreaks clustering in specific areas, causing immune individuals to group together. This clustering reduces the overall protective effect of immunity on the broader population. When people are physically close, they’re more likely to catch the disease from each other, making disease-induced immunity less effective in these networks.
When we look at the way people are wired together, many connections are shaped by physical proximity—such as in households, workplaces, or neighborhoods—which amplifies the localization effect and limits the protective reach of immunity across the broader population. The right side of Fig. 7 illustrates spatial network models where connections are more likely to form between physically close people. In homogeneous networks, where individuals have roughly the same number of connections, localization tends to outweigh the benefits of preferential immunity. In such cases, random vaccination often proves more effective than natural infection for achieving herd immunity, as it distributes immunity more evenly across the network. However, in more heterogeneous networks—where some individuals have significantly more connections than others—disease-induced immunity gains an advantage. When highly connected individuals become infected and then immune, they can help slow transmission. Still, localization remains a factor, as outbreaks can cluster within certain areas, limiting the network’s overall protective effect.
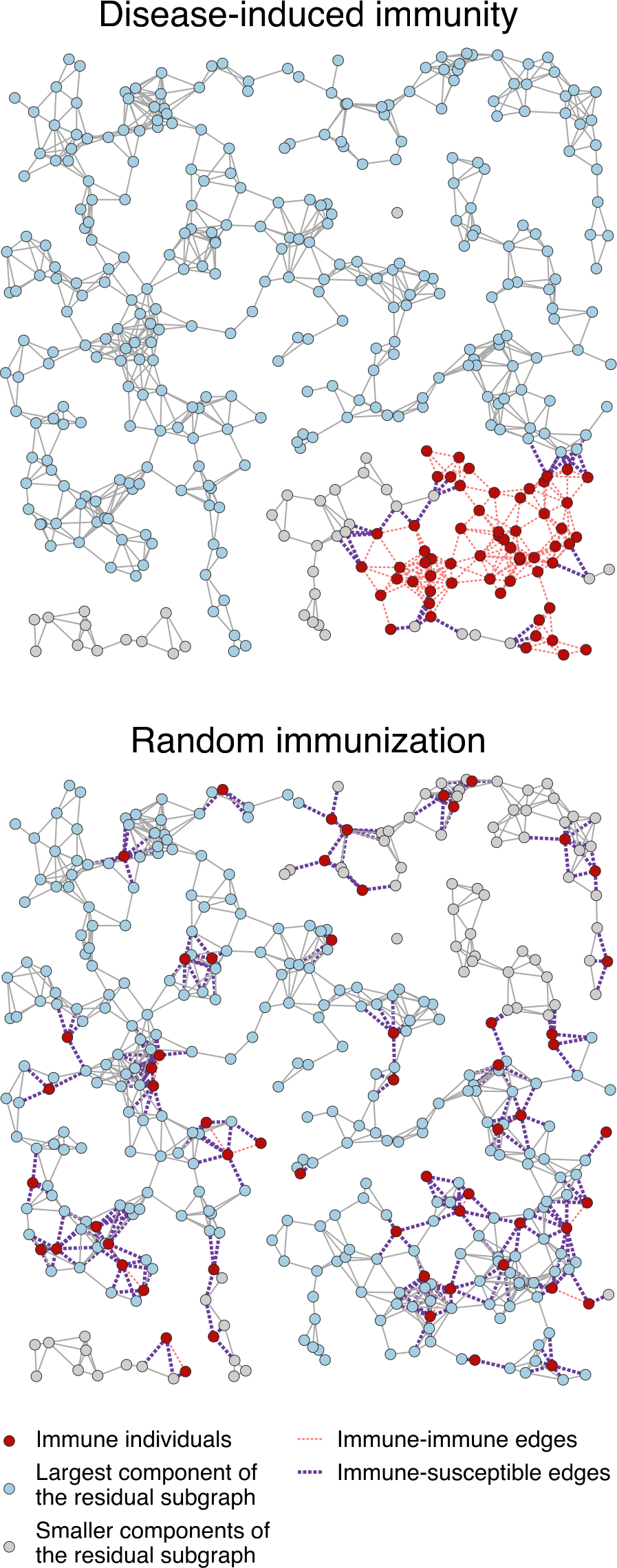
Fig. 8: Comparison between the distributions of the same number of immune individuals (nodes) induced by an epidemic and by vaccination (random immunization) in a random geometric graph.
Random geometric graphs bridge the gap between purely random graph models and real-world networks with spatial constraints, providing a useful framework in various fields, from communication networks to biology and epidemiology.
This illustrates how disease-induced immunity propagates through a network, with red dots representing immune individuals—those who have recovered from infection and can no longer transmit the disease. The blue dots are still susceptible and make up the largest connected group at risk of an outbreak. Gray dots represent smaller groups of people who are more isolated from the main network.
As part of the Nordic Pandemic Preparedness Modelling Network—a Nordic collaboration focused on creating data and modeling tools to support pandemic preparedness—wetested this spatial approach using real-world data from Finland. We created a realistic social network that accurately reflected life in Finland, incorporating age structure and interactions among different age groups. Simulating an epidemic on this network, we found that even after reaching what traditional models would consider the herd immunity threshold, the disease could still resurge, particularly in networks with strong spatial organization.
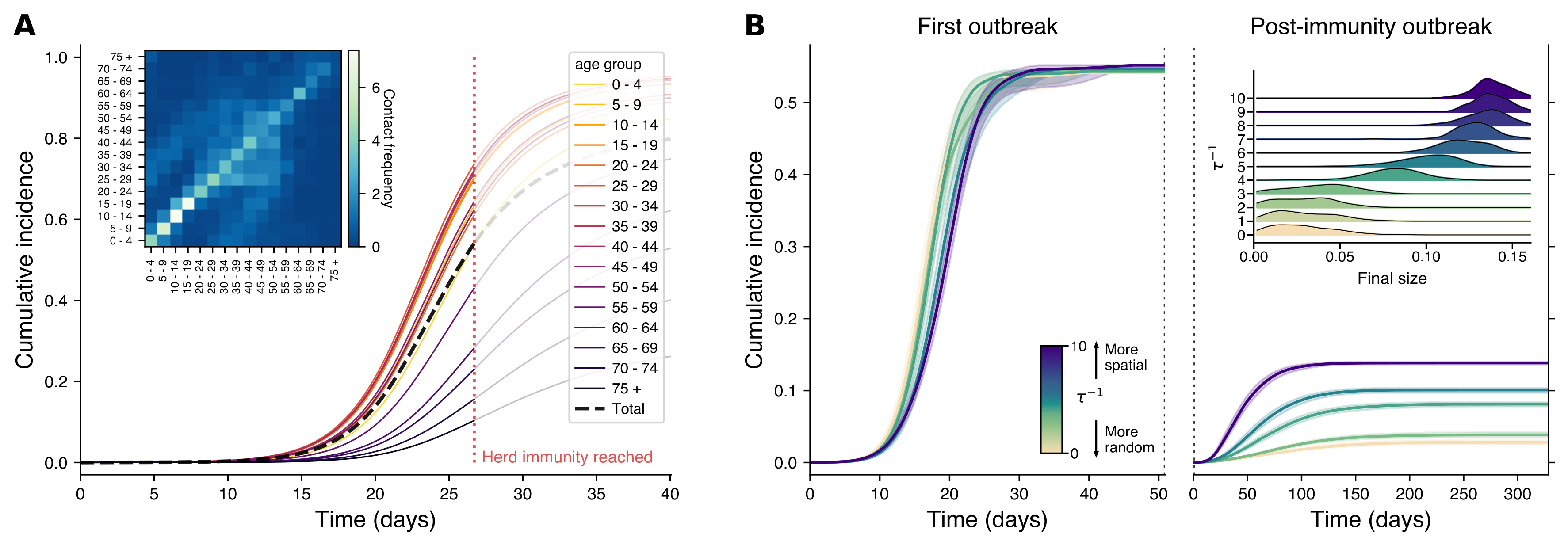
Fig. 9: How Epidemics Spread in Different Network Models, Using Data from Finland. pnas.2421460122#fig04
Panel A of Fig.9 shows a traditional model that treats the population as if everyone mixes evenly, with cumulative cases tracked by age group. The black dashed line shows total infections over time, and the red dotted line marks when herd immunity is theoretically reached. The inset displays how often different age groups interact in Finland. In Panel B, we see a more realistic network model based on the Finnish social network, where people are more likely to connect with those nearby. The left plot shows the initial outbreak, while the right captures what happens if the disease is reintroduced after reaching herd immunity. The colors represent different levels of ‘spatiality’ in the network: light colors show more random mixing, while darker colors represent networks where people stick closer to home. The inset on the right shows that even with herd immunity, localized outbreaks can still happen, especially in more spatially organized networks. The spatial structure is represented by varying $\tau^{-1}$ values, from random (light colors) to highly spatial (dark colors), with shaded areas representing the 95% confidence intervals across simulations.
So, what does this mean for the debate between vaccination and natural infection?
The key takeaway is that neither approach is universally better—it all depends on the network structure. In more uniform (homogeneous) networks, random vaccination tends to be more effective for achieving herd immunity, while in highly varied (heterogeneous) networks, disease-induced immunity can offer certain advantages by naturally targeting superspreaders. The reality lies in between. To improve public health models, we need to consider network structures, as traditional models often underestimate the immunity levels required for herd protection. Understanding real-world social connections can make vaccination campaigns more effective by using network analysis to identify high-risk communities or individuals. This enables more strategic, data-driven interventions, targeting those most likely to drive transmission and optimizing resource allocation.
Read the supporting material for this post here:
Strength and Weakness of Disease-induced Herd Immunity in Networks, PNAS
I defended my DSc thesis, Spreading and Epidemic Interventions: Effects of Network Structure and Dynamics, on Friday, March 15, 2024, at noon in the T2 hall of the Department of Computer Science at Aalto University.
Opponent: Nicola Perra, Queen Mary University of London, United Kingdom
Custos: Mikko Kivelä, Aalto University School of Science, Department of Computer Science
You can access an online version of my dissertation via this link.
What is my thesis about?
Spreading and Epidemic Interventions
Effects of Network Structure and Dynamics
Mathematical modeling has significantly improved our understanding of how infectious diseases spread and how interventions can be effective. Over time, these models have become more complex, capturing intricate phenomena related to diseases like HIV, flu, and even computer viruses. With our experiences during global health crises like COVID-19, it has become increasingly important to accurately model transmissions via social networks when planning epidemic responses. Traditional epidemic models often overlook the structured nature of social connections. However, this work aims to bridge this gap by contributing to the literature by incorporating the networked structure of human populations into epidemiological modeling.
The thesis focuses on network epidemiology, a field that benefits from mathematical and computational modeling to analyze how social structures influence disease transmission and the success of intervention strategies such as vaccination, contact tracing, and social distancing. This work explicitly explores how particular aspects of social network structure can impact disease spread and the effectiveness of public health measures. Additionally, the research introduces a new mathematical framework for studying how any spreading agent spreads across dynamic networks. This framework provides a foundation for exploring various spreading phenomena beyond epidemics, paving the way for further research.
The insights presented in this thesis are expected to offer valuable clues to individuals interested in modeling and navigating future epidemics. It emphasizes the significance of adopting epidemic models that recognize the intricate relationship between human behavior, social structures, and disease dynamics.
Illustrations of my public defense session by Mikhail Shubin
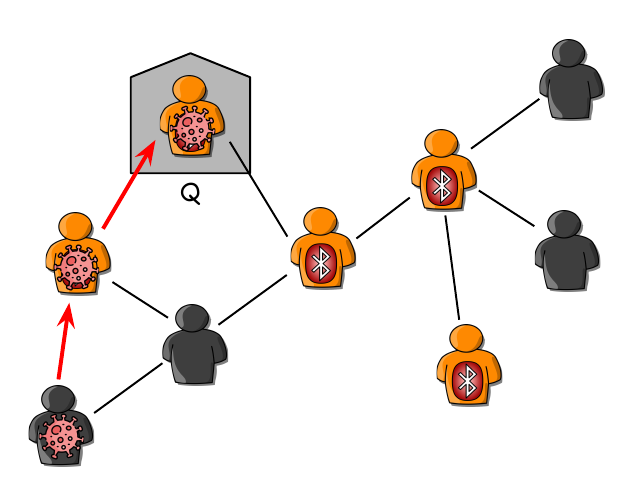
An example of a path of infection: the second app-user has received an exposure notification and has isolated her/himself since s/he can be infectious!
Since the beginning of the COVID-19 pandemic, dozens of countries have deployed contact tracing via smartphone apps to employ quarantine for individuals who are at risk of infecting others. The idea behind digital contact tracing is to use smartphone applications to inform people who have been close to infectious people who also use the same application. Data from a handful of nations show mounting evidence that digital contact tracing is useful in keeping the spread of infectious diseases at bay.
Using the toolbox of network science, K. Rizi et al. have investigated the effectiveness of this low-cost intervention method on models that assume more realistic assumptions about human populations. Their model makes it possible to see when and how large an outbreak can happen if a fraction of people adopts the contact tracing apps given several different heterogeneities in the population structure. Importantly, their model includes homophily in the application adoption: the tendency of people who use the application to be more in touch with each other than people who do not use the application. Their results indicate that contact tracing with apps raises the epidemic threshold and reduces the size of the emerging outbreaks. Their results bring this issue to light that digital contact tracing can curb the pandemic even if it is not done perfectly, but its effects are highly nonlinear and strongly dependent on how the connections are structured among application users and others.
K. Rizi, Abbas, et al. “Epidemic spreading and digital contact tracing: Effects of heterogeneous mixing and quarantine failures.”
Time: Monday 13.01.2020 13.30 – 14.00 Place: Meeting room A142, T-building Speaker: Abbas K. Rizi Citation: Rizi AK, Zamani M, Shirazi A, Jafari GR and Kertész J (2021) Stability of Imbalanced Triangles in Gene Regulatory Networks of Cancerous and Normal Cells. Front. Physiol. 11:573732. doi: 10.3389/fphys.2020.573732
Received: 17 June 2020; Accepted: 16 December 2020; Published: 20 January 2021.
Balance Theory of Signed Genetic Interactions Reveals Differences in Cancerous and Healthy Cells
Abstract:
Genes are not independently functioning in the cell and their expressions are strongly correlated with each other. They communicate with each other through different regulatory effects which lead to the emergence of complex structures in the cells. Such structures are expected to be different for healthy and cancerous cells. To study the differences in the case of breast cancer, we have investigated the Gene Regulatory Network (GRN) of cells as inferred from the RNA-sequencing data using the maximum entropy principle. The GRN is a signed weighted network corresponding to the inductive or inhibitory interactions. In this presentation, I will focus on a particular set of motifs in the GRN, the triangles, which can be imbalanced if the number of negative interactions in them is odd or balanced otherwise. I will show that the network in cancerous cells has fewer imbalanced triangles than in the healthy case. Moreover, in the healthy cells, imbalanced triangles are isolated from the main part of the network, while such motifs are part of the giant component of the network in cancerous cells.
To obtain the estimator in programs, users could use GraphLasso() function in Python Scikit-Learn package.
Matlab implementation of the graphical Lasso model for estimating sparse inverse covariance matrix (a.k.a. precision or concentration matrix)
Data
The data of mRNA (expression level) of 20532 genes in the case of Breast Cancer (BRCA: Breast invasive carcinoma) has been downloaded from The Cancer Genome Atlas (TCGA) project. For each gene, there exist 114 normal and 764 cancerous samples, and the expression levels have been measured with the technique of RNA sequencing (RNA-Seq). We have used the RPKM (Reads Per Kilobase transcript per Million reads.) normalized data. RPKM combines the concepts of normalizing by sample and by gene. When we calculate RPKM, we are normalizing for both the library size (the sum of each column) and the gene length. We had to reduce the number of genes because it is a difficult task to handle a 20532 by 20532 matrix computationally. For each gene, we have calculated the variance of its expression level over its samples, and finally, we have stored the first 483 genes with the highest variance due to more different activity patterns these genes show among the others. Note that there are so-called housekeeping genes that typically get transcribed continually. These genes are required for the maintenance of basic cellular function and are expressed in all cells of an organism under normal and patho-physiological conditions. Some housekeeping genes are expressed at relatively constant rates in most non-pathological situations.
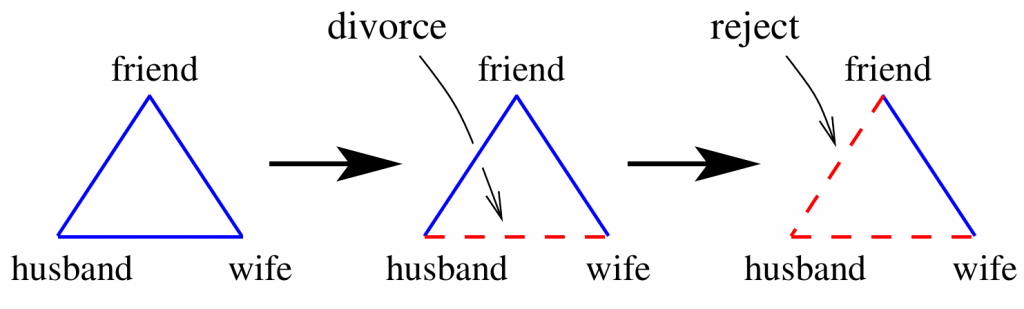
Imagine Alice and Bob have just gotten married and have a mutual friend called Chris. In this scenario, they form a triangle of husband-wife-friend relationship, and every edge of this triangle represents a friendship link. Obviously, in this triplet of relationships, people like each other and can spend time together without any conflicts! So this triplet is said to be balanced because everything is fine there, and people enjoy their current state. But If something goes wrong between Alice and Bob and they decide to get divorced, then the link between the husband and wife in the triangle turns into enmity, and from now on, this change makes Chris rethink his relationship with this ex-couple because he cannot simultaneously be friend with these guys who are enemy of each other! Chris has to change his attitude towards Alice or Bob; at last, he must decide to be in a friendship status only with one of them. The triplet of the relationship is now imbalanced, and Chris finally decides to turn his relationship with Alice or Bob into enmity (turning a positive link into a negative one), which leads to another balanced state for this triangle of relationship after experiencing an imbalance. The dynamics of this change are mimicked in the picture below.
Evolution of a married couple plus friend triplet. After a divorce the triangle becomes imbalanced, but balance is restored after another relationship change. Full and dashed lines represent friendly (+) and unfriendly (-) relations respectively. REF: arXiv:physics/0605183
So as you may guess, in a triplet of relationships, if odd numbers of the links are positive (friendship), the triangle is said to be balanced, and otherwise, it is imbalanced. A balanced triangle, therefore, fulfills the adage that: (i) a friend of my friend is my friend, (ii) an enemy of my friend is my enemy, (iii) a friend of my enemy is my enemy, and (iv) an enemy of my enemy is my friend. This notion of balance in social systems was first introduced by Heider (1946), an Austrian psychologist whose work was related to the Gestalt school.
The Energy of Social Networks
The key concept in Heider’s Balance Theory is, “We adjust our relationship based on reducing the psychological stresses.” On the other hand, an imbalanced triangle is analogous to a frustrated plaquette in a random magnet. Physicists know how to assign energy to a system based on the interactions of its constituents. Therefore, inspired by a random magnet, we can assign energy to a triplet of relationships by multiplying each link’s strength in the triangle of relationships. So in the case of the husband-wife-friend triangle, the energy is:
$$E = -R_{hw}R_{wf}R_{fh}$$
which $R_{hw}$ is the strength of the relationship between husband and wife. For a friendly relationship, $R_{hw}$ is a positive number, and $R_{hw}$ is a negative number for an unfriendly relationship. The minus sign is to make the analogy between the concept of social balance and stability in physics. In physical terms, the imbalanced triangles must have higher energy because the dynamics are toward more stable states with lower energy levels. The same reason that an apple falls off a tree and goes from a higher energy level at a higher altitude to lower energy levels toward the ground.
Now with this mechanism, calculating the energy of triangles formed in a social network is handy; we can just simply find the energy of each triangle and, by aggregating them, come to the energy of that network! The higher energy of a network, the more tendency toward attitude change is expected in that network!
The Cancerous Cell Has Less Energy!
When we look at the social life of the genes in the cell, we see that genes make dialogue with each other. It means that genes form a social network in a cell and that the relationships between each pair of genes can be positive or negative, in the sense that genes can alter the state of other genes through the so-called regulatory effects. So, again if the strength of the relationship between each pair of genes is known, we can find the cell’s energy. For the case of Breast Cancer, K. Rizi et al. at Shahid Beheshti University in Tehran have inferred the strength of the relationship between each pair of genes and showed that the energy level of the normal cell is higher than the cancerous one, meaning the normal cell has more tendency to change its attitude. Therefore it can tackle more challenges it experiences through its life cycle.
This is how interdisciplinary research is done nowadays in complex systems. The point is to be open to ideas from different disciplines and creative enough to construct a pathway to solve real-world problems. From a psychological theory from 1946, we have come to a question in 21st-century systems biology with a resolution equipped with the physics toolbox!
"I prefer movies. ... I prefer myself liking people to myself loving mankind. ... I prefer the color green. ... I prefer moralists who promise me nothing...." Wisława Szymborska